
Is condition monitoring right for you?
Making your systems smarter with automated condition monitoring
- Have you ever had one of your machines, systems or assets go down without warning?
- Have you ever wondered if you could minimize these headaches?
- Are you innovative?
Condition monitoring may be able to help solve your problems.
Introduction
Condition monitoring of machines and systems has been around in some form for several decades. Early forms of monitoring and analysis were manually done by humans. A person would take measurements (e.g. various probes) or inspect the system with their available sensors (e.g. eyes, ears, hands). Sometimes this monitoring took place on periodic intervals, and other times only after a significant problem had occurred within the system. The evolution of processing capabilities along with the proliferation of various sensor technologies has historically allowed very expensive and mission-critical systems (e.g. military aircraft) to be monitored in conjunction with regular system operation. Given the constant introduction of new technology and lower price of entry, this technology can and will be implemented in more and more systems.
In this whitepaper we will provide some basic answers to the following questions:
- When should I consider implementing condition monitoring?
- What types of physical properties can be sensed?
- What types of components can be monitored?
- What types of information can be produced?
- How do I translate the information into decisions?
This last item is where benefits come into play.
The role of humans in the monitoring process is evolving from direct probing and measurement to higher level analysis and specification of techniques and requirements. As in many cases in our ever-advancing society, humans will likely continue to lean on machines to do the more menial, repetitive, error prone, and dangerous tasks, while humans focus on more complex and creative sorts of tasks.
As systems gain intelligence, it will become more and more important to build in safety mechanisms and feedback loops. It is imperative that these tightly or loosely coupled feedback loops don’t trigger catastrophic events like a flash crash resulting from an unstable system.
When to consider condition monitoring
Typical candidates for condition monitoring include large industrial machines, equipment, and structures. More specifically, this can be broken into two main environments:

From a product or system lifecycle perspective, similar to typical product development, there are three main points in which condition monitoring may be injected:
- To instrument existing systems to collect data to justify incorporation into future designs
- To augment existing systems
- To build monitoring into new designs
More generally, any system that meets the desired return-on-investment (ROI) is a candidate for condition monitoring. ROI can and should attempt to account for straightforward factors such as direct downtime costs, as well as more complex factors, such as customer satisfaction, employee retention, and environmental impact.
There are three primary reasons to consider condition monitoring:
- Reduced downtime (which increases throughput, profit, and staff and customer satisfaction)
- Increased safety (which drives down insurance costs and minimizes lawsuits)
- Improved environmental impact (by reducing manufacturing waste or preventing impending structural failures)
The stakeholders for considering condition monitoring may include some of the roles outlined in the below diagram:
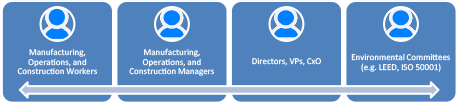
Making the choice to incorporate condition monitoring is, at a high level, similar to other decisions made in the business environment. However, there may be more indirect or complex costs to consider in the process. Consider the following direct and indirect costs to help determine the ROI for a particular system. Understanding loaded labor rates, cost-of-goods-sold (COGS), and various strategic goals (e.g. employee retention, customer satisfaction, environmental initiatives) will prove useful during this exercise.

TAKE AWAY: WHEN TO CONSIDER CONDITION MONITORING
Does ROI justify it? The ROI should consider both direct and indirect costs, stemming from complex factors such as safety, employee retention, customer satisfaction, and competitive advantage.
What information can be sensed
In order to determine the condition of any aspect of a system, it is necessary to first measure some physical property. It is often desirable to sense information that can act as a leading indicator before the system becomes inoperable. There are numerous types of sensors, each of which measures a physical property in a particular manner, and then transduces that measurement into an electrical signal that can be processed by electronic systems.
Here is a list of some physical properties that can be sensed, along with some corresponding sensors:
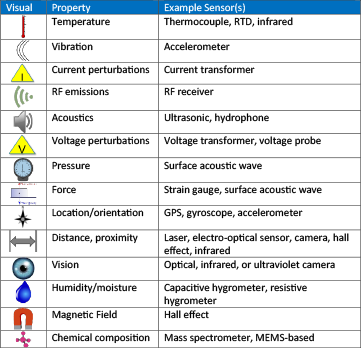
Many sensors are available in miniaturized form factors — or will be over the coming years — through the utilization of MEMS technology, allowing for implantation of more and more sensing devices.
Important specifications for sensor selection include:
- Accuracy and resolution
- Dynamic range
- Minimum detectable signal
- Response rate and bandwidth
Other requirements to consider may include:
- Environmental specifications (e.g. temperature, shock, vibration)
- Size, weight, and power (SWaP)
- Mounting options
- EMI/EMC compliance
Interfacing to the sensor to get accurate digital data to a processor can be quite involved and require significant expertise. Transduced signals often need signal conditioning (e.g. amplification, filtering), and then sampling, processing, alignment, and formatting prior to being utilized by the main monitoring algorithms.
Calibration is an important topic, but will not be discussed in this paper as it is a more in-depth technical discussion.
TAKE AWAY: INFORMATION TO SENSE
Nearly any physical property can be sensed. The challenge that condition monitoring can address is accuracy in sensing and in maintaining the integrity of that information.
What components can be monitored
Most components that exhibit a physical property that can be sensed can also be monitored. This is straightforward as a high-level concept, but proper implementation is not always simple. In addition, just because component properties can be monitored, does not mean that component anomalies can easily be detected.
So which components should be monitored? The most relevant components to monitor are often those that act as the best early indicators of larger issues to come. Therefore, a solid understanding of the failure modes is important.
If you don’t know which components are good candidates to be monitored, a common technique is to instrument up a system with more sensors than are needed, collect a lot of data, and analyze the data to find the best indicators. Often the shape of a signal can be more important than the value. Time is another dimension in data collection that is implicit, but very useful. Think about short-duration waveforms and long-duration trending.
This list contains example components that are possible candidates for monitoring:
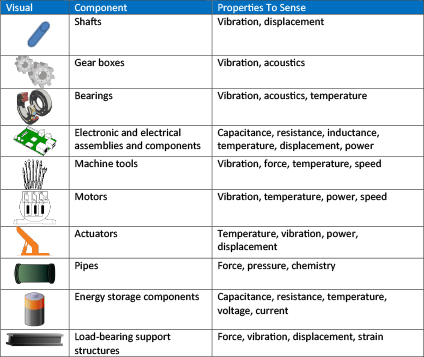
The best indicators aren’t always the easiest components to monitor. Monitoring components often involves detecting changes that are:
- Subtle and small
- Really slow or really fast
- Located in electrically noisy environment, resulting in low signal-to-noise ratio (SNR)
Additionally, the sensor may be challenging to mount because of:
- Rotating components
- A mounting location that blocks machine operation
- A challenging mounting surface for long-term mounting
TAKE AWAY: COMPONENTS TO MONITOR
Component monitoring selection must take into consideration the ability to detect changes, the ability to detect them early, and the ability to mount the sensor.
What information can be produced
Information is produced through various signal and data processing algorithms and techniques. Processing may consist of many forms of heuristic algorithms, utilizing multi-sensor homogenous and heterogeneous data fusion, M-of-N processing, rapid change detection, profile matching, order analysis, cross-correlation with known-good data, and time- and frequency-domain thresholds and windowing. Beyond this, there are several more advanced processing techniques, including those within the realm of machine learning and related domains of processing (e.g. IMS – Watchdog Agent).
In order to perform the desired signal and data processing, it is very important to choose a platform with the right processing capabilities. FPGAs, GPGPUs, DSPs and μPs are common processor categories. Appropriate selection depends largely on the algorithms utilized. Questions revolving around the following will help drive the decision process:
- Timing determinism and response time
- The type of operations (floating point vs. fixed point, trigonometry, divides)
- Parallel vs. sequential processing
- Interface and communication with other systems
Heterogeneous platforms (e.g. those with a combination of multiple types of processing elements such as an FPGA with a μP) are becoming more common and allow for the strengths of both platforms. In fact, some platforms are utilizing system-on-chip (SoC) technologies that combine an FPGA with a μP. A few examples of heterogeneous processing platforms include:
Various forms of detection algorithms can produce status information, warning flags, and alerts to indicate that some component of the system is outside of the specified bounds.
In a few, very well-understood cases, Remaining Useful Life (RUL) can predict — with particular confidence intervals — how much time a particular component, sub-system, or system has left before action must be taken.
TAKE AWAY: INFORMATION
Signal and data processing can range from simplistic to very sophisticated. The algorithms chosen vary widely based on objectives, level of understanding of the problem, and project funding.
What decisions can be made?
At this point, depending on the confidence level of the information provided by the condition monitoring system, a decision may be made to either:
- Investigate further
- Stop a machine to prevent destruction
- Halt production, construction, vehicle or rail traffic, or shut off valves in pipes, depending on the type of system being monitored
Currently most decisions are simple go/no-go, intended to reduce the probability of more severe events occurring, or to sound an alert that a serious event is occurring or had occurred.
Condition monitoring is an area of active research for the early detection of subtle effects. No one should base their use of condition monitoring on these subtle effects. Without collecting and saving the data, detecting these subtle effects will never be available. Start collecting data now!
If monitoring is being performed for data collection purposes to determine what to monitor on future designs, be sure the information is well-indexed and contains appropriate metadata so that context can be determined.
Optimization of facility or site operations is another important use of condition monitoring. The resulting information can be utilized to help improve efficiency in areas such as electrical power consumption and machine maintenance.
TAKE AWAY: DECISION MAKING
Ultimately condition monitoring can help you decide when to take action regarding a particular system and which components should be modified in future designs. If you are new to condition monitoring, start collecting data now!
Looking forward and next steps
As our systems become smarter, more automated, and more interconnected, it will become more and more important to understand the overall condition of the system in order to make better decisions. Cyber-physical systems will become more intertwined with our lives and productivity.
To develop a complete solution, it is important to factor in considerations that arise for many electronic systems: signal and component interfacing, enclosures and housings, SWaP, and lifecycle support. A solid engineering development process is essential and should involve requirements definition, system architecture, electronics design, software development, unit test, system integration and test. A knowledge base within the domains of systems engineering, electronics engineering, and software development are important.
As a result of implementing condition monitoring, benefits such as increased throughput, cost reductions, happy bosses, happy workers, happy customers, and environmental conservation can be achieved. These factors can improve the health of your company in the long run. If you have a condition monitoring challenge that your curious how we’d tackle, feel free to reach out to us.