

Online Condition Monitoring – How to Get Started – A Practical Guide for OEMs
Do you have a pretty good sense that Online Condition Monitoring can help you out, but aren’t sure where to begin or what pitfalls you might come across?
This guide will offer up steps you can take to start moving forward. We’ll provide info on:
- How to go about building a business case for OCM
- Deciding what to monitor with your OCM sub-system
- How to develop a Pilot program for OCM
INTRODUCTION
Let’s start by defining online condition monitoring. In this context, online condition monitoring (OCM) is defined as the utilization of measurement hardware and software to continuously check the state of a system, a machine, or a process, generally with the end goal of reducing downtime, increasing efficiency, or reducing waste. These goals are accomplished by producing a set of indicators (events, faults, and alarms) that suggest an action, such as look further into a potential problem, shut down a piece of equipment, perform maintenance, or collect additional data.
It’s also important to define and differentiate an OEM (Original Equipment Manufacturer) versus an end-user of CM (Condition Monitoring). If you manufacture industrial equipment, machines, or infrastructure and have interest in putting condition monitoring into systems that you sell, you’re considered an OEM. If on the other hand, you work at a manufacturing / generation / distribution / processing plant and have interest in putting condition monitoring into systems you operate internally, you’re an end-user. This guide is focused on the OEM scenario.
BUILDING THE BUSINESS CASE
 If you have already been given the go-ahead to implement OCM, or if you already know how to justify OCM, then you can skip this section. For those of you that are not sure how to go about justifying OCM, my suggestion is this: utilize the minimum amount of effort necessary. If it makes sense to spend weeks crunching numbers, then so be it, but if it makes sense to tie OCM into a corporate-level initiative (e.g. around efficiency or quality), then go that route.
If you have already been given the go-ahead to implement OCM, or if you already know how to justify OCM, then you can skip this section. For those of you that are not sure how to go about justifying OCM, my suggestion is this: utilize the minimum amount of effort necessary. If it makes sense to spend weeks crunching numbers, then so be it, but if it makes sense to tie OCM into a corporate-level initiative (e.g. around efficiency or quality), then go that route.
The level of management buy-in required to proceed will vary significantly, depending on the level of business impact expected from implementation of an OCM system. Justification can be quantitative and/or qualitative.
Quantitative justification
You’ll need to gather information about the direct, and indirect, impacts of not having OCM on downtime, efficiency, and waste.
This information is scenario-dependent, but many will fall into one or more of these categories:
- Customer uptime / efficiency / waste – This applies if your customers care about how often your machine goes down and if you can tell them in advance. You’ll need to dig in to understand the cost impact on your customer in order to better understand the additional cost that they could justify for an OCM-enabled product.
- Maintenance or warranty services – if you offer these services to your customer, here are a few opportunities. You could:
- Reduce labor and travel costs by doing more remote diagnostics, only sending out a tech when needed. You’ll need a good handle on your current labor, travel, and possible warranty costs.
- Increase your market penetration by allowing for a more non-linear expansion of number of systems you could provide services for versus number of additional employees you might need to hire. You’ll need to have a good handle on your current labor, travel, and support equipment costs.
- Modify repair schedules based on both yours and your customer’s appetite for risk. This of course requires you to understand the trade-off between material costs, services costs, and costs associated with system failure.
- Future design improvements – if you’ve got many systems instrumented over a long period of time, and in an operational environment, you can gather data and statistics that act as a feedback loop for future generations of your product. Information gathered may inform you to loosen or tighten specs on a particular component, or drive you to change a design or a supplier.
|
KEY POINT: Future design improvements You can gather data and statistics that act as a feedback loop for future generations of your product. |
Unfortunately, there is generally no easy way for this information to appear at your fingertips. You’ll want to gather information about: labor, travel, downtime, and material costs. This information will come from several business systems and will require speaking with several people, then manually aggregating data. You’ll need to use this aggregated information as a rough cost target for the condition monitoring sub-system. This should only be used as a ROM (rough order of magnitude) estimate. Anything beyond that will likely be wasted effort at this point.
In parallel, you’ll want to develop a ROM estimate for unit costs of the OCM system. You can then iterate throughout the pilot program to converge on a workable solution.
Qualitative Justification:
After reading through the quantitative justification section, you may think that’s your path to success. Not necessarily. If you can justify your case for OCM qualitatively, you may be able to shorten the process to getting your OCM pilot off the ground. Of course, if it makes sense in your scenario, you can always pull both qualitative and quantitative elements to help make your case. Below are some qualitative motivators to consider.

|
KEY POINT: Quantitative & Qualitative justification Don’t limit yourself to trying to come up with a single number for whether or not it makes sense to implement OCM. It may require a combination of quantitative and qualitative elements. |
DECIDING WHAT TO MONITOR
At the end, what you functionally get out of condition monitoring are a series of indicators (faults, alarms, events), that inform you (via a text message, email, or HMI (Human-Machine Interface) to take some sort of action (shut down a piece of equipment immediately, inspect a system further, or start collecting additional data for off-line analysis). These indicators stem from observable physical component properties. Start from both ends, and work your way toward the middle: algorithms.
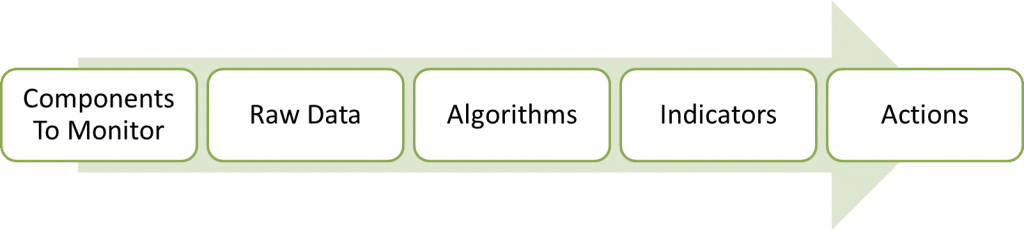
Think about what actions you’d like to be able to take, and work that back into what indicators will be needed. This will drive the sorts of observations that need to be made by the OCM.
The core of the detection algorithms are essentially trying to differentiate (for a given feature) between what you define as a good state and a bad state.
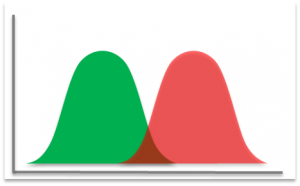
But what if you don’t already have a solid understanding of how to detect a good and bad state for a particular feature? If you’ve not done so already, this starts with a FMECA (Failure Mode, Effects, and Criticality Analysis). This will give you a better sense of each type of failure, its detectability, and its importance. You’ll likely be designing some experiments, instrumenting multiple systems, and collecting a lot of data. This knowledge will be used for subsequent algorithm development.
Reliable Early Detection Indicators (REDI)
Most components that exhibit a physical property that can be sensed, can also be monitored. However, being able to monitor properties does not mean that you can easily detect component faults. All other things being equal, you want to monitor properties that are the earliest indicators of larger issues to come. Monitoring components often involves detecting changes that are:
- Subtle and small
- Really slow or really fast
- Located in electrically noisy environments
We want to find the right balance between minimizing false positives and false negatives. What makes a fault reliably detectable? Three things:
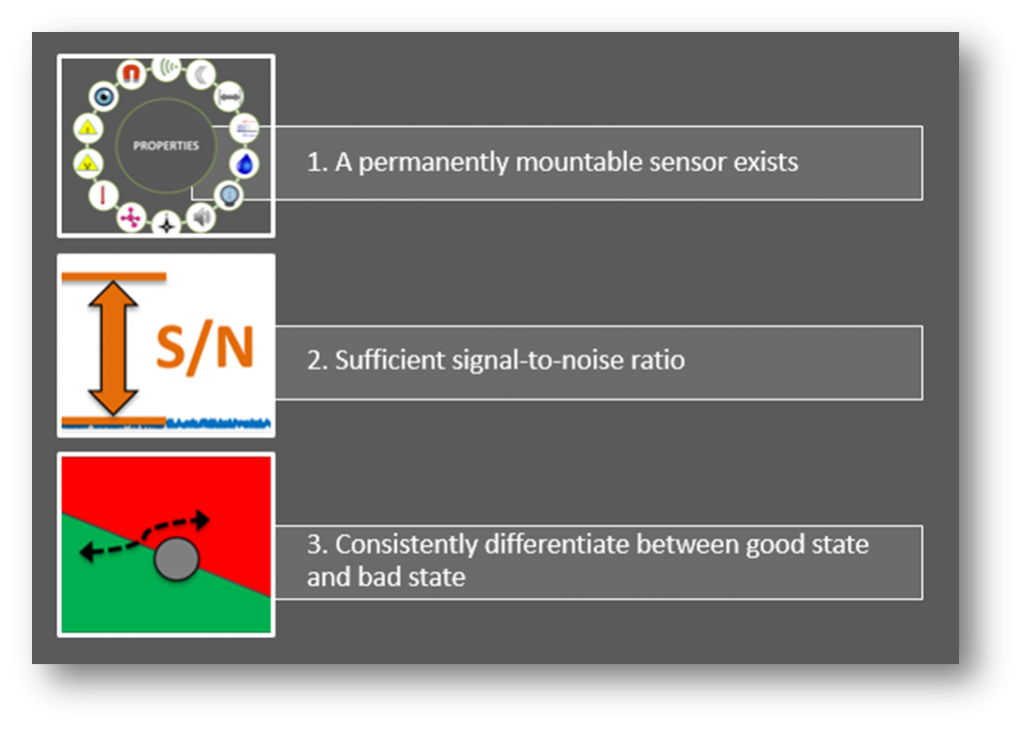
And what do we mean by early indicator? We mean that if this plot is showing performance degradation of a system over time, where we cross from the good state to the bad state at the x-axis, we’d like to know as soon as possible that something is going on.

|
KEY POINT: Reliably Detectable Early Indicators What makes a component/sub-system/system a good candidate for OCM? A reliably detectable early indicator. |
INITIATE A PILOT PROGRAM
A pilot program is your opportunity to prove out what you think you know based on the pieces of the puzzle that you’ve gathered. You’ll need to strike a balance between starting without enough information at hand (totally in the dark), and waiting until you have high confidence that it will work (paralysis by analysis).
The following steps will help you initiate a solid pilot program:

The sections below explain these steps in detail.
Define success criteria – define what success will look like at the end of the pilot program.
This step is critical, since it’s the indicator to your organization that it either makes sense to proceed with another pilot, roll out, or squash the program and go back to the drawing board.
Some potential success criteria might include:
- Able to detect X fault in sub-system Y in order to take action Z, A% of the time under condition B.
- Developed an algorithm that will detect sub-system fault X in order to take action Y, Z% of the time under condition W.
- Compared two sets of sensors and algorithms to determine the best performance and compare compared with our existing manual methods
Create a Statement of Work – help develop a mental model.
A formal SOW is not necessary, but you’ll want to include some basic information to get everyone on the same page. Define the team and team member rolls to encourage individual responsibility and reduce finger pointing. Provide a basic timeline with maybe ~four milestone dates to target. This will keep everyone marching toward the goal. Depending on your scenario, you may or may not need to track cost at this point. Your previously defined success criteria can go into the SOW as well.
Develop the OCM Algorithms –
In this step you need to lay out the likely algorithm structure and data flow for your OCM algorithms. The outputs from this step (depending on complexity of the OCM algorithms) will be a block diagram and/or PC-based code (e.g. C, MATLAB, LabVIEW).
This step may seem a bit out of order, as requirements generation is shown after this step, and it seems like requirements would be needed in order to develop algorithms. This is an iterative aspect of the development process. Your previous FMECA analysis will provide a starting point for indicator requirements, but further refinement will likely be required post algorithm development. You may need to modify requirements revolving around processor capabilities, sensor requirements, or measurement requirements, among others.
Algorithm development approaches may combine:
- Well-established detection methods for certain types of component faults
- Heuristics based on empirical data collection
- Physics-based models of components
You’ll likely be working with real data collected from the system to refine knowledge gained from your FMECA-oriented experiments. The results of this phase will be a set of simulation results. This phase will help you decide whether to:
- Move forward with implementation of the algorithm you developed or
- Go back to the drawing board, possibly looking at other features, fusing multiple properties, or maybe analyzing the utility of some crazy elegant CM algorithm.
Generate a requirements and specification document –
This is the sort of document that (at least at this stage of the game) you want to keep as minimal as possible, while still conveying useful information. This is not a production program, it’s an R&D effort, so there will be many unknowns and several fuzzy specs up front, but that’s okay. Capture what you know and what you believe to be the case.
Where to start:
- Are there any existing requirements from previous analysis work or similar past efforts?
- What existing sensors do you have in place or have you tried on similar systems?
- What existing data do you have to pull from?
- Is there an existing controller within the system under consideration that you can piggyback off of, or do you need to augment with a separate monitoring system?
Main requirements and specification sections:

Design, implement, integrate and test hardware and software –
At this point, the engineering flow is very similar to a typical embedded system development project. A couple of important points to highlight are:
- Consider having a solid algorithm analysis and development person as part of the team, as there will be some unexpected head scratchers along the way.
- Depending on the architecture and requirements of your main embedded electronics and the needs of your OCM system, you may be able to combine the base hardware from the embedded controller and just add in the required measurement inputs. This approach can reduce overall system costs.
- You may need to accelerate the fault modes of the system being monitored (similar in concept to HALT/HASS).
If the results from your pilot program are questionable from a statistical validity standpoint, consider one of the following next steps:
- Try enhancing or utilizing alternative CM algorithms (e.g., look for common approaches, connect with a CM algorithm consultant or research center, consider data fusion and heuristics) extract different features, or sense different physical properties.
- Instrument your systems going to the field with data collection capabilities to gather more real-world data over a longer period of time
Generate a summary report –
This step is critical. You need to summarize your findings while everything is fresh in your mind. Add context to the data. Augment with opinions. The report should consist of the following sections:
- Executive summary (written last, and with easy-to-follow visuals)
- Risks and concerns
- Indicator test results
- Indicator test setup
- Unit cost estimates
LOOKING FORWARD AND NEXT STEPS
Making OCM stick: the first step toward scaling and expanding is by preventing a slow fade away into irrelevance. Show its value. Often the value of CM is in having something bad NOT happen. Tying OCM back to its original business case motivators should help. Gather the same metrics that initially suggested OCM and compare them after some long period of time with the pre-OCM results to analyze the expected improvements.
If OCM has been shown to be valuable within a particular product, by all means, start scaling up. Try not to do this as a step function, as new problems will arise that weren’t seen in the pilot program. A phased approach is recommended.
Presumably if you’re reading this white paper, you have interest in the potential that OCM has to offer. More than likely, there is still some uncertainty and unknowns. If you’d like to discuss the specifics of your scenario, feel free to reach out to us.